Tugas System Berkas
TEKNIK KALKULASI ALAMAT
Tugas System BerkasDosen: LULU CHAERANI MUNGGARAN
kelas : 2IA05
Nama Anggota:
1. Dodi Riyawan (504 08 953)
2. Assarianto (504 08 173)
3. Sriadi (504 08 805 )
Teknik Kalkulasi Alamat
R(NILAI KEY) <> ADDRESS.
Adalah dengan melakukan kalkulasi terhadap nilai key, hasilnya adalah alamat relatif. Ide dasar dari kalkulasi alamat adalah mengubah jangkauan nilai key yang mungkin, menjadi sejumlah kecil alamat relative. Salah satu kelemahan dari teknik pengalamatan relative adalah ruang harus disediakan sebanyak jangkauan nilai key, terlepas dari berapa banyak nilai key. Salah satu masalah dari teknik ini adalah ditemukannya alamat relative yang sama untuk nilai key yang berbeda. Seperti di bawah ini adalah maksud dari keadaan itu;
Keadaan dimana :
R(K1) = R(K2) Disebut benturan atau
K1 ¹ K2 collision
Sedangkan nilai K1 dan K2 disebut synonym.
Ket : Synonim merupakan dua atau lebih nilai key yang berbeda pada hash ke home address yang sama.
Teknik-teknik yang terdapat pada kalkulasi alamat :
Dalam teknik kalkulasi terdapat macam – macamnya dan sebagai berikut;
- Scatter storage techniques
- Randomizing technique
- Key-to-address transformation methods
- Direct addressing techniques
- Hash table methods
- Hashing
Teknik Hashing
Akan di jelaskan keuntungan dan kerugian dari teknik ini;
Keuntungan pemakaian Hashing :
- Nilai key yang sebenarnya dapat dipakai sehingga dapat di terjemahkan ke dalam sebuah alamat.
- Nilai key merupakan address space independent bila berkas direorganisasi, fungsi hash berubah tetapi nilai key tetap.
Kelemahan dati hasing :
- Distribusi nilai key yang dipakai
- Banyaknya nilai key yang dipakai relative terhadap ukuran dari ruang alamat
- Banyaknya record yang dapat disimpan pada alamat tertentu tanpa menyebakan benturan
- Teknik yang dipakai untuk mengatasi benturan
Penampilan fungsi hash bergantung pada :
- Distribusi nilai key yang dipakai
- Banyaknya nilai key yang dipakai relative terhadap ukuran dari ruang alamat
- Banyaknya record yang dapat disimpan pada alamat tertentu tanpa menyebabkan benturan
- Teknik yang dipakai untuk mengatasi benturan
Beberapa fungsi hash yang umum digunakan :
- Division Remainder
- Mid Square
- Folding
KEY TO ADDRESS TRANSFORMATION METHODS
Teknik yang digunakan dalam teori mengoreksi kesalahan-kode ini diterapkan untuk menyelesaikan masalah menangani file besar. dalam Pendekatan baru ini ke file menangani masalah digambarkan dengan desain khusus untuk menampilkan kelayakan. dari Efektivitas merupakan lebih lanjut diilustrasikan dengan membandingkan hasil uji yang diperoleh dari simulasi perhitungan, yang menggunakan data khas, terhadap nilai-nilai dihitung dari model yang ideal.
DIRECT ADDRESSING
Semua instruksi lain yang diperlihatkan menggunakan pengalamatan langsung, yang berarti bahwa data yang direferensikan sebenarnya disimpan dalam struktur lain - baik sebuah register atau lokasi memori.
TABEL HASH
Adalah merupakan struktur data yang menggunakan fungsi hash untuk efisien peta pengidentifikasi tertentu atau kunci (misalnya, nama-nama orang) untuk dihubungkan nilai (misalnya, nomor telepon mereka). Fungsi dari hash digunakan untuk mengubah kunci ke indeks (hash) dari array elemen (dalam slot atau ember) dimana nilai yang sesuai yang akan dicari.
Dalam banyak situasi, tabel hash ternyata lebih efisien daripada pohon pencarian atau lainnya tabel struktur lookup. Untuk alasan ini, mereka banyak digunakan di berbagai jenis komputer perangkat lunak , terutama untuk array asosiatif , pengindeksan database , cache , dan set .
Keuntungan
Keuntungan utama dari tabel hash atas struktur tabel data lainnya adalah kecepatan. Keuntungan ini lebih jelas ketika jumlah entri yang besar (ribuan atau lebih). tabel Hash dapat sangat efisien ketika jumlah maksimum entri dapat diprediksi dari sebelumnya, sehingga ember array dapat dialokasikan sekali dengan ukuran optimal dan tidak pernah diubah ukurannya.
2. Jika himpunan pasangan kunci-nilai adalah tetap dan dikenal lebih dulu sehingga insersi dan penghapusan tidak diijinkan, yang dapat mengurangi biaya rata-rata lookup pilihan hati-hati dari fungsi hash, ember ukuran meja, dan struktur data internal. Secara khusus, satu mungkin dapat menyusun fungsi hash yang tabrakan-bebas, atau bahkan sempurna.
Kerugian
1. Untuk aplikasi pengolahan string tertentu, seperti spell-checking , tabel hash mungkin kurang efisien daripada mencoba , automata terbatas , atau array Judy . Juga, jika setiap tombol diwakili oleh sejumlah kecil bit yang cukup, maka, bukan sebuah tabel hash, yang dapat menggunakan tombol langsung sebagai indeks ke array nilai.
2. Meskipun rata-rata biaya per operasi adalah konstan dan cukup kecil, dengan biaya operasi tunggal dapat cukup tinggi. Secara khusus, jika tabel hash menggunakan ukuran dinamis , penyisipan atau penghapusan operasi yang memerlukan waktu sebanding dengan jumlah entri.Hal ini dapat di katakan kelemahan yang serius secara real-time atau aplikasi interaktif.
3. Hash tabel dalam pameran umumnya miskin pemukiman referensi -yaitu, data yang akan diakses didistribusikan tampaknya secara acak di memori. Hal ini Karena tabel hash menyebabkan pola akses berupa melompat-lompat, ini dapat memicu cache mikroprosesor yang menyebabkan penundaan yang lama. struktur data seperti array, mencari dengan pencarian linear , akan lebih cepat jika meja relatif kecil dan tombol yang integer atau string singkat lainnya.
4. Tabel Hash menjadi sangat tidak efisien bila ada banyak tabrakan. Sementara itu hash distribusi yang tidak merata sangat tidak mungkin muncul secara kebetulan, seorang dengan pengetahuan dari fungsi hash mungkin dapat memberikan informasi untuk hash yang menciptakan perilaku-kasus terburuk dengan menyebabkan tabrakan yang berlebihan, yang mengakibatkan kinerja yang sangat buruk yaitu, sebuah serangan penolakan layanan . Dalam aplikasi kritis, baik universal hashing dapat digunakan atau struktur data dengan jaminan terburuk lebih baik mungkin lebih disukai.
SCATTER STORAGE TECHNIQUES
Sebuah metode dan aparatus untuk melakukan penyimpanan dan pengambilan dalam suatu sistem penyimpanan informasi yang diungkapkan menggunakan teknik hashing. Untuk mencegah kontaminasi dari media penyimpanan dengan secara otomatis berakhir catatan, teknik pengumpulan sampah digunakan yang menghapus semua berakhir catatan di lingkungan dari penyelidikan ke dalam sistem storge data.. Lebih khususnya, masing-masing probe untuk penyisipan, pengambilan atau penghapusan merekam adalah kesempatan untuk mencari seluruh rangkaian catatan ditemukan untuk catatan berakhir dan kemudian menghapusnya dan menutup rantai.Koleksi ini sampah secara otomatis menghapus catatan kontaminasi berakhir di sekitar probe, sehingga secara otomatis decontaminating ruang penyimpanan.. Karena tidak ada kontaminasi jangka panjang dapat membangun dalam sistem ini, akan sangat berguna untuk basis data yang besar yang banyak digunakan dan yang memerlukan akses cepat disediakan oleh hashing.
RANDOMIZING TECHNIQUE
Meskipun secara historis "teknik pengacakan" manual (seperti menyeret kartu, gambar potongan kertas dari tas, memintal roulette wheel) yang umum, saat ini teknik otomatis sebagian besar digunakan. . Seperti kedua memilih sampel acak dan permutasi acak dapat dikurangi menjadi hanya memilih nomor acak, nomor acak generasi sekarang metode yang paling umum digunakan, baik hardware nomor acak generator dan nomor acak generator-pseudo .
metode pengacakan Non-algoritmik meliputi:
• Casting Yarrow batang (untuk I Ching )
• Lempar dadu
• Menggambar sedotan
• Shuffling cards Mengocok kartu
• Roulette wheels Roulette roda
• Menggambar potongan kertas atau bola dari kantong
• " Lottery mesin "
key to address transformation methods
Teknik yang digunakan dalam teori mengoreksi kesalahan-kode ini diterapkan untuk menyelesaikan masalah menangani file besar. Pendekatan baru ini ke file menangani masalah digambarkan dengan desain khusus untuk menunjukkan kelayakan. efektivitas adalah lebih lanjut diilustrasikan dengan membandingkan hasil uji yang diperoleh dari simulasi perhitungan, yang menggunakan data khas, terhadap nilai-nilai dihitung dari model yang ideal.
Terkait Subjek: Kode dan coding; kode koreksi Kesalahan
scatter diagram techniques
Scatter Diagram Techniques
Bagaimana memahaminya
Ketika menyelidiki masalah, biasanya ketika mencari penyebab mereka, dapat diduga bahwa dua item yang terkait dalam beberapa cara. Misalnya, dapat diduga bahwa jumlah kecelakaan kerja berkaitan dengan jumlah lembur yang orang yang bekerja.
Diagram Scatter membantu untuk mengidentifikasi adanya hubungan terukur antara dua item tersebut dengan mengukur mereka berpasangan dan merencanakan mereka pada grafik, seperti di bawah ini. Visual ini menunjukkan korelasi antara dua set pengukuran.
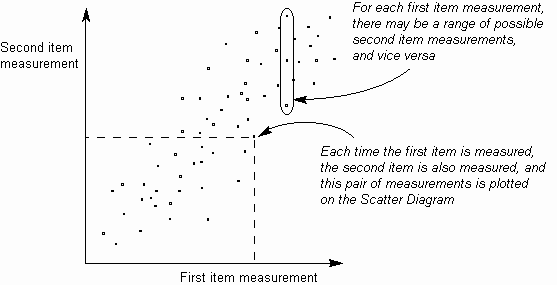
Gambar. 1. Poin pada Scatter Diagram
Jika poin digambarkan pada Diagram Scatter tersebar secara acak, tanpa pola yang jelas, maka ini menunjukkan bahwa dua set pengukuran tidak berkorelasi dan tidak dapat dikatakan berhubungan dengan cara apapun. If, however, the points form a pattern of some kind, then this shows the type of relationship between the two measurement sets. Namun, jika titik-titik membentuk pola dari beberapa jenis, maka ini menunjukkan jenis hubungan antara dua set pengukuran.
Sebuah Scatter Diagram menunjukkan hubungan antara dua item untuk tiga alasan:
- Dua item yang diukur adalah baik disebabkan oleh item ketiga. Misalnya, Scatter Diagram yang menunjukkan korelasi antara celah-celah dan transparansi peralatan kaca karena perubahan baik disebabkan oleh perubahan suhu tungku.
- Kebetulan Lengkap. Hal ini dimungkinkan untuk menemukan korelasi tinggi item yang tidak terkait, seperti jumlah semut persimpangan jalan dan penjualan koran.
Scatter Diagram sehingga dapat digunakan untuk memberikan bukti hubungan sebab dan akibat, tetapi mereka sendiri tidak membuktikannya. Biasanya, hal itu juga memerlukan pemahaman yang baik sistem yang akan diukur, dan mungkin diperlukan percobaan tambahan. 'Sebab' dan 'efek' dengan demikian dikutip dalam bab ini untuk menunjukkan bahwa meskipun mereka dapat diduga memiliki hubungan ini, belum diketahui secara pasti.
Sewaktu mengevaluasi Diagram Scatter, baik tingkat dan jenis korelasi harus dipertimbangkan. Yang terlihat perbedaan Scatter Diagram untuk ini ditunjukkan dalam Tabel di bawah ini.
Di mana ada hubungan sebab-akibat, tingkat tersebarnya diagram mungkin akan dipengaruhi oleh beberapa faktor (seperti yang diilustrasikan dalam diagram di bawah ini):
- Kedekatan dari sebab dan akibat.
- Beberapa penyebab efek. Ketika mengukur satu penyebab, penyebab lainnya adalah membuat efek tersebut sangat beragam dengan cara yang tidak terkait. Penyebab lainnya mungkin juga memiliki efek yang lebih besar, swamping efek sebenarnya penyebab tersebut.
- Alam Variasi dalam sistem. Efeknya mungkin tidak bereaksi dengan cara yang sama setiap kali, bahkan penyebab utama dekat.
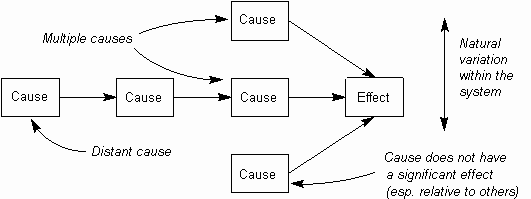
Gambar. 2 Kompleks menyebabkan
Tidak ada gelar yang jelas salah satu hubungan di atas mana suatu hubungan yang jelas dapat dikatakan ada. Instead, as the degree of correlation increases, the probability of that relationship also increases. Sebaliknya, sebagai tingkat korelasi meningkat, kemungkinan hubungan yang juga meningkat.
Jika ada korelasi yang cukup, maka bentuk Diagram Scatter akan menunjukkan jenis korelasi (lihat Tabel @ @). Yang paling umum adalah bentuk garis lurus, baik miring ke atas (korelasi positif) atau miring bawah (korelasi negatif).
| Scatter Diagram | Derajat | Interpretasi |
|
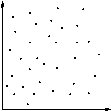
| Tidak ada | Tidak ada hubungan dapat dilihat. tidak terkait dengan 'menyebabkan' dengan cara apapun. |
|
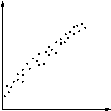
| Rendah | Hubungan samar terlihat. Itu karena 'dapat mempengaruhi' efek ', tapi hanya jauh. |
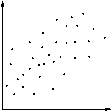
|
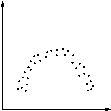
| Tinggi | Poin yang dikelompokkan menjadi bentuk linier jelas. Ini adalah kemungkinan bahwa karena 'secara langsung berkaitan dengan efek'. Oleh karena itu, setiap perubahan karena 'akan menghasilkan perubahan ditebak cukup dalam' efek '. |
|
| Perfect Sempurna | Semua poin yang terletak pada baris (yang biasanya lurus). Mengingat 'menyebabkan nilai, sesuai efek' 'nilai dapat diprediksi dengan kepastian lengkap. |
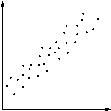
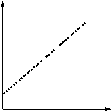
| Scatter Diagram | Jenis | Interpretasi |
|
| Positif | Garis lurus, miring dari kiri ke kanan. Meningkatkan nilai karena 'hasil dalam peningkatan proporsional dalam nilai' efek '. |
|
| Negatif | Garis lurus, miring turun dari kiri ke kanan. Meningkatkan nilai karena 'hasil penurunan proporsional nilai dari' efek '. |
|
| Lengkung | Berbagai kurva, biasanya U-atau S-berbentuk. Mengubah nilai karena 'hasil dalam' efek 'berubah berbeda, tergantung pada posisi pada kurva. |
|
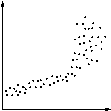
| Bagian linier | Bagian dari diagram adalah garis lurus (miring ke atas atau bawah). Mungkin karena kerusakan atau kelebihan dari 'efek', atau kurva dengan bagian yang mendekati ke garis lurus (yang mungkin diperlakukan seperti itu). |
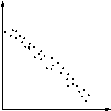
Poin yang muncul baik di luar daerah terlihat tren mungkin karena sebab khusus dari variasi, dan harus diteliti seperti itu.
Selain interpretasi visual, beberapa perhitungan dapat dilakukan sekitar Scatter Diagram. Perhitungan yang dibahas disini adalah untuk korelasi linear; kurva memerlukan tingkat matematika yang berada di luar cakupan buku ini.
- Koefisien korelasi memberikan nilai numerik untuk tingkat korelasi. Hal ini akan bervariasi dari -1, yang menunjukkan korelasi negatif sempurna, melalui 0, yang menunjukkan korelasi sama sekali, ke +1, yang menunjukkan korelasi positif yang sempurna. Jadi nilai lebih dekat adalah plus atau minus 1, korelasi yang lebih baik. Dalam korelasi sempurna, semua poin berbaring di garis lurus.
- Sebuah garis regresi membentuk 'paling cocok' atau 'rata-rata' dari diplot poin. Hal ini setara dengan mean dari distribusi (lihat Variasi Bab ).
- Kesalahan standar adalah setara dengan standar deviasi dari suatu distribusi (lihat Variasi Bab ) dalam cara yang menunjukkan penyebaran efek mungkin 'nilai-nilai untuk setiap satu karena nilai.
Dihitung angka berguna untuk menempatkan nilai numerik pada perbaikan, dengan 'sebelum' dan 'nilai-nilai setelah'. Mereka juga dapat digunakan untuk memperkirakan berbagai kemungkinan efek '' nilai-nilai dari sebab yang diberikan '' nilai-nilai (asumsi hubungan sebab akibat terbukti). Angka di bawah ini menunjukkan bagaimana garis regresi dan kesalahan standar dapat digunakan untuk memperkirakan kemungkinan efek '' nilai dari penyebab tunggal 'diberi nilai.

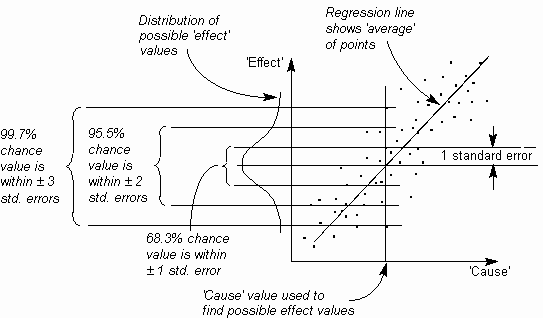


Fig. Gambar. 3 Distribusi titik-titik di Scatter Diagram
Contoh
Sebuah tim perencanaan
Untuk mendapatkan ukuran yang cukup, mereka membuat tindakan setiap hari selama dua bulan, menggunakan sensor jalan lokal dan laporan dari layanan ambulans. Scatter Diagram digambar untuk setiap penyebab yang mungkin terhadap jumlah kecelakaan. Hasil memungkinkan kesimpulan berikut harus dibuat:
*
*
* Ada korelasi, positif dengan kecepatan tinggi lalu lintas, dengan kecelakaan dropping off lebih tajam di bawah 30 mph.
Akibatnya, langkah-langkah kontrol kecepatan lebih banyak lalu lintas yang dipasang, termasuk tanda-tanda dan permukaan. Hal ini mengakibatkan penurunan terukur dalam kecelakaan.
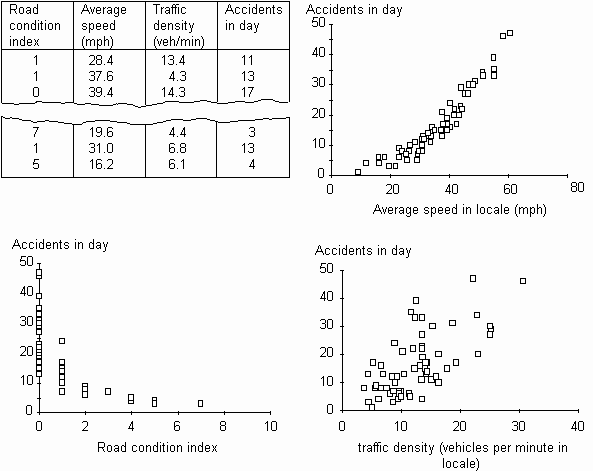
Gambar. 1. Contoh Scatter Diagram
Contoh lainnya
* Seorang tukang roti tersangka bahwa waktu berdiri dari adonan mempengaruhi cara naik. Sebuah Diagram Scatter waktu bangkit melawan kepadatan roti diukur menunjukkan korelasi yang adil pada distribusi berbentuk U terbalik. Dengan demikian ia menggunakan waktu pada titik tertinggi pada kurva untuk mendapatkan kesempatan terbaik roti baik-bangkit.
* Diduga bahwa suhu tekan menyebabkan menolak dalam proses pembentukan plastik. Sebuah Diagram Scatter menunjukkan korelasi positif yang tinggi, mendorong suatu redesign pers, termasuk penggunaan bahan lebih tahan panas. Hal ini menghasilkan penurunan yang signifikan dalam jumlah potongan ditolak.
* Sebuah plot gaji departemen SDM terhadap hasil survei motivasi. Hasilnya adalah korelasi negatif yang lemah. Sebuah Scatter Diagram kedua, merencanakan waktu di perusahaan terhadap motivasi, memberikan korelasi yang lebih tinggi. Sebuah program motivasi ditargetkan sesuai dan menghasilkan peningkatan yang stabil dalam skor yang diberikan kepada motivasi dalam survei personil berikutnya perusahaan.
Bagaimana melakukannya
1. Tentukan dua item yang ingin Anda bandingkan. Satu dapat diidentifikasi sebagai penyebab dicurigai dan yang lain sebagai efek dicurigai. Hal ini mungkin berasal dari penggunaan alat-alat lain, seperti Efek-Penyebab Hubungan Diagram atau Diagram.
2. Identifikasi pengukuran yang akan diambil. Keduanya harus variabel (yaitu diukur pada skala kontinu) dan itu harus mungkin untuk mengukur keduanya pada saat yang sama.
Buatlah pengukuran sespesifik mungkin untuk mengurangi variasi dan meningkatkan kemungkinan hubungan yang lebih tinggi. Sebagai contoh, pengukuran dari bahan pemasok tunggal mungkin lebih baik daripada mengukur semua bahan yang disediakan.
3. Membuat 50-100 pasang pengukuran. Ketika melakukan hal ini, bertujuan untuk menjaga semua variabel lain stabil mungkin, karena dapat mengganggu dengan angka akhir.
Berhati-hatilah ketika mengukur perilaku manusia, sebagai tindakan pengukuran dapat menyebabkan orang diukur untuk mengubah perilaku mereka, terutama jika mereka mencurigai mereka mungkin kehilangan keluar dalam beberapa cara.
4. Plot diukur pasang di Scatter Diagram. Desain sumbu dan sisik pada diagram untuk memberikan penyebaran maksimum visual poin. Ini mungkin melibatkan menggunakan skala yang berbeda dan membuat sumbu salib di non-nilai nol (seperti pada gambar dibawah).
Jika menyelidiki hubungan sebab-akibat yang mungkin, alur sebab dicurigai pada sumbu x (horizontal) dan efek dicurigai pada sumbu y (vertikal).
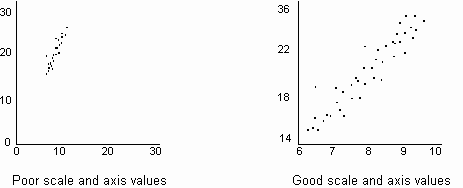
Gambar. 1. Pengaturan skala
5. Jika korelasi tinggi, kemunduran ('rata-rata') line dapat ditarik melalui titik merencanakan, untuk menekankan tren. Hal ini dapat dihitung atau diperkirakan dengan mata (meskipun hal ini harus dibuat jelas bagi pembaca masa depan diagram).
6. Jika korelasi cukup linear, maka koefisien korelasi dapat dihitung.
7. Menafsirkan diagram dan bertindak sesuai. Hal ini mungkin untuk mengidentifikasi perbaikan atau untuk memungkinkan estimasi nilai efek masa depan. Jika yang terakhir, standard error dapat dihitung, seperti pada gambar di bawah ini.
Bila menggunakan Scatter Diagram untuk memperkirakan nilai dampak masa depan, hanya memperkirakan dalam kisaran korelasi diketahui, sebagai bentuk dapat berubah di luar kisaran tersebut.
Praktis variasi
* Jika titik pada Diagram Scatter bertepatan dengan poin lainnya, fakta bahwa satu titik sebenarnya adalah dua atau lebih mungkin akan disorot oleh keberanian mereka atau dengan menggunakan lingkaran konsentris.
* Jika pengukuran sulit diperoleh, sesedikit 30 pasangan pengukuran dapat digunakan.
* Gunakan Tabel Korelasi ketika kebetulan beberapa poin diukur, biasanya ketika ada sejumlah posisi mungkin. Ini secara efektif lintas antara Scatter Diagram dan Check Sheet, dimana setiap posisi xy diwakili oleh kotak di mana beberapa poin dapat diindikasikan.
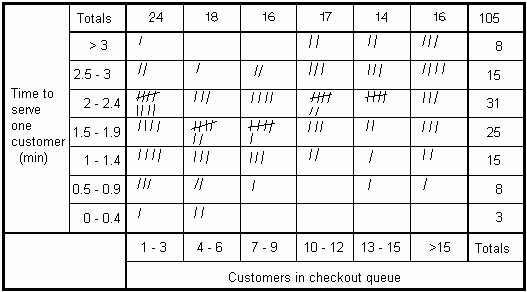
Gambar.1 Tabel Kolerasi
* Pisahkan set pengukuran dapat ditampilkan pada Diagram Scatter yang sama, yang dapat dibedakan dari satu sama lain dengan menggunakan spidol berbentuk berbeda untuk setiap set poin. Pemakaian khas adalah di mana satu variabel yang sedang berubah, misalnya untuk menunjukkan pengukuran bahan dari pemasok yang berbeda.
* Mana korelasi non-linear muncul, perkiraan kasar dapat dilakukan dengan menggunakan mereka dengan membagi mereka ke dalam bagian sekitar linear dan menghitung garis regresi dan standard error seperti di atas.









Tidak ada komentar:
Posting Komentar